○=O 一=E 二=R 三=S 四=F 五=W
六=L 七=C 八=B 九=K 十=J
入門篇
規則說明
嘸蝦米的規則,非常簡單,就只有四個字,「截長補短」。何謂「截長補短」的規則呢?其實提到的是兩個規則:「截長」是限制嘸蝦米字根拆碼,最多只能到四個碼;而「補短」,指的是除了數字之外,只要一個字只取到兩個以下的字根,就要進行補根。
而在詳細介紹「截長補短」的同時,有幾個嘸蝦米規則的使用要領,要一起說明給大家,所以在這個單元,我們分為三個部分來說明:
1. 大根原則
2. 截長補短
3. 取碼順序
大根原則
所謂的「大根原則」,就是在取碼的時候,優先取筆畫較多的字根。例如「李」字,有人說「木子李」,也有人說是「十八子李」。嘸蝦米輸入法是以較大根先取為原則,取「木子李」,而不取「十八子李」,因為「木」的筆劃比「十」的筆劃多。(本輸入法名曰「嘸蝦米」,即源於此意思是說,要取大根,不要取「蝦米根」。)例如:
(買)字,取(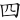 、
、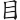 、
、 )三碼 = FMB
)三碼 = FMB
(較)字,取(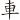 、
、 、
、 )三碼 = CLX
)三碼 = CLX
(蒞)字,取( 、
、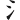 、
、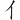 、
、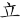 )四碼 = RWPL
)四碼 = RWPL
(輪)字,取(、 、
、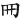 )三碼 = CAM
)三碼 = CAM
(部)字,取(、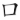 、
、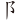 )三碼 = LOB
)三碼 = LOB
(新)字,取(、 、
、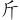 )三碼 = LTK
)三碼 = LTK
(薪)字,取(、、、)四碼 = RLTK
(給)字,取( 、、)三碼 = SAO
、、)三碼 = SAO
(能)字,取( 、
、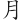 、
、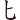 、)四碼 = UUFF
、)四碼 = UUFF
(哈)字,取(、、)三碼 = OAO
(咖)字,取(、 、)三碼 = ODO
、)三碼 = ODO
(啡)字,取(、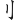 、
、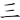 、)四碼 = ORSS
、)四碼 = ORSS
(宗)字,取(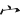 、
、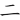 、
、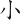 )三碼 = NRS
)三碼 = NRS
(綜)字,取(、、、)四碼 = SNRS
(吃)字,取(、 、
、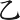 )三碼 = OVZ
)三碼 = OVZ
(菲)字,取(、、、)四碼 = RRSS
(奇)字,取( 、
、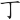 、)三碼 = DTO
、)三碼 = DTO
(寄)字,取(、、、)四碼 = NDTO
(邵)字,取(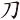 、、)三碼 = DOB
、、)三碼 = DOB
(員)字,取(、、)三碼 = OMB
以上的例子若還不能體會,再舉一個很明顯的例子,相信在了解這個例子後,應該會有更深刻的體會。
大家學習到現在,一定已經拆過了「天」這個字。您是如何拆解「天」字呢?是拆解為「 、 」,取「EDN」嗎?的確,拆解為「EDN」可以打出「天」字。不過正確的拆法為「
、 」,取「EDN」嗎?的確,拆解為「EDN」可以打出「天」字。不過正確的拆法為「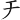 、
、 」,取「GNN」。之所以要這樣取,正是因為大根原則,一開始要優先取筆劃較多的字根。
」,取「GNN」。之所以要這樣取,正是因為大根原則,一開始要優先取筆劃較多的字根。
至於何以不正確卻還能打出「天」字,這正是先前曾提到的「包容式編碼」!「EDN」正是「天—GNN」的容錯碼。
「截長補短」
嘸蝦米輸入法的「截長補短」,顧名思義是把太長的截去,而把較短的補上,這是是嘸蝦米組字規則當中最重要的部分。其中又以「補短」較需要注意。
截長
每一個字,最多只取四個碼,依照順序先取頭三個碼。再跳取最後的尾碼,如中間尚有筆劃,則將其省略,此謂之「截長」。例如:
(機)字,取(、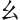 、、
、、 )= TWWB,此處的(
)= TWWB,此處的( )(
)(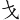 )省略。
)省略。
(敵)字,取(、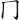 、
、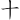 、
、 )= LNJP,而把()省略。
)= LNJP,而把()省略。
(靈)字,取( 、、、
、、、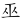 )= UOOW,將一個()省略。
)= UOOW,將一個()省略。
(腳)字,取(、、、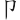 )= UBBP,將()省略。
)= UBBP,將()省略。
(歸)字,取( 、
、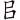 、
、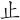 、
、 )= PBZN,將(
)= PBZN,將(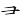 )與(
)與( )省略。
)省略。
補短
相較於「截長」,「補短」較需要用心去注意。如果一個字,取不到三個碼的話,這個字就要補上一枚「補根」。換句話說,一個字,若只取得一碼或兩碼,都算是短的,都要補根(數字除外),此謂之「補短」。一個字,如果只取得一個根,就要加上一枚「補根」,所以是兩碼字。一個字,如果只取得兩個根,也要加上一枚「補根」,就變成三碼字。一個字,如果已取得三個根,不必加「補根」,也就是三碼字。一個字,如果已取得四個根,不必加「補根」,則為四碼字。「數目字」從○到十,共十一個數目字全不加「補根」,為一碼字。
不過,若只談「最後一筆」這樣的概念,可能在某些筆畫上,還是會有些爭議。因此定下「最後一筆」包括底下十一種類型:

【注意】所謂明顯的斜交型,是指與直交型有所區別的,我們以該字根的下面,是否有被其他的字根所阻擋,作為分別。例如:(南)與(直)等字,是取直交型的(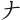 ),南=JNBG,直=JML。而右與左等字則是取斜交型,右=XOO,左=XIE。同理,(石)字是取(
),南=JNBG,直=JML。而右與左等字則是取斜交型,右=XOO,左=XIE。同理,(石)字是取( )字根,而(頁)字則先取(
)字根,而(頁)字則先取( )字根。例如:苦=RJO,若=RXO,石=LOO,頁=TMB。
)字根。例如:苦=RJO,若=RXO,石=LOO,頁=TMB。
底下補充一些需要補根的例字:
(方)字是F根,僅取得一個根,補根(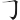 )為Y,(方)字全碼是FY
)為Y,(方)字全碼是FY
(火)字是F根,僅取得一個根,補根()為N,(火)字全碼是FN
(上)字是F根,僅取得一個根,補根()為E,(上)字全碼是FE
(下)字亦F根,僅取得一個根,補根()為A,(下)字全碼是FA
(立)字是L根,僅取得一個根,補根()為E,(立)字全碼是LE
(車)字是歸C根,補根是直交的 () 是為J,(車)字全碼是CJ
(仿)字,取(、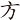 )兩個根,補根()為Y,(仿)字全碼是PFY
)兩個根,補根()為Y,(仿)字全碼是PFY
(伙)字,取(、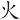 )兩個根,補根是N,(伙) 字全碼是 PFN
)兩個根,補根是N,(伙) 字全碼是 PFN
(口)字,取() 一根,補根亦是()為O,(口) 字全碼是 OO
(合)字,取(、)兩個根,補根是O,(合)字全碼是 AOO
(名)字,取( 、)兩個根,補根是O,(名)字全碼是 COO
、)兩個根,補根是O,(名)字全碼是 COO
(酒)字,取(、 )兩個根,補根是O,(酒)字全碼是 WEO
)兩個根,補根是O,(酒)字全碼是 WEO
(雷)字,取(、 )兩個根,補根是O,(雷)字全碼是 UQO
)兩個根,補根是O,(雷)字全碼是 UQO
(昔)字,取(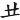 、
、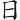 )兩個根,補根是O,(昔)字全碼是 RDO
)兩個根,補根是O,(昔)字全碼是 RDO
(出)字,取(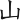 、)兩個根,補根是I,(出)字全碼是 EEI
、)兩個根,補根是I,(出)字全碼是 EEI
(放)字,取(、)兩個根,補根是X,(放)字全碼是 FPX
而中文的數目字○、一、二、三、四、五、六、七、八、九、十,有其特殊性。使用頻率很高,嘸蝦米輸入法也將它做特別的設定,該十一個字,不另加補根。也就是說:用一碼即可得一個中文數目字,如字根表中的:
如不做為數字用時,就要恢復常態。例如:
(仁)字,取(、)兩個根,補根為()=E, (仁)= PRE
(伍)字,取(、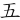 )兩個根,補根為()=E, (伍)= PWE
)兩個根,補根為()=E, (伍)= PWE
取碼順序
嘸蝦米輸入法的取碼順序,原則上,是按照一般書寫的順序來取碼,在大部分的情形下,按照筆畫順序由上而下,由左而右、由外而內的原則來取碼,不會有太大的問題。
眼順大於筆順
不過中國字的筆畫有時候會有些例外,再加上每個人對於筆順的學習可能有些出入,可能不易按照筆順的方式來取碼。若有這類狀況,則直接直接以「眼順」的方式,一眼看出上、下、左、右,就可以解決取碼順序上的問題。簡單來說就是「眼順大於筆順」。
①如遇三個字根平頭並列的字,如(彎)字、(變)字、(燕)字等,則先左而後右取碼。
例如:
(獄)字,取(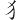 、
、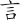 、、) = QIAD
、、) = QIAD
(彎)字,取(、、、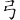 ) = SISQ
) = SISQ
(變)字,取(、、、) = SISP
(燕)字,取(、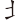 、、
、、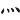 ) = RFOF
) = RFOF
(樂)字,取(、、、) = WPDT
②三個字根不平頭的字,如(兆)字,(非)等,則較高出的根先取。意思是說:先由上而下,由左而右的順序取碼。
例如:
(兆)字,取(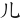 、
、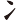 、
、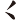 ) = RBB
) = RBB
(非)字,取(、、) = RSS
③如果一個「點」在某一個字根的上方時(不管在左上方或是右上方),則先取「點」。
例如:
(魷)字,取(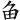 、、、
、、、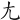 ) = UFAK
) = UFAK
相反的,如果「一點」是在於下方或含內,則該「點」後取。
例如:
(玉)字,先取(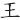 ),次取() = KAA
),次取() = KAA
(叉)字,先取(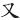 ),次取() = UAA
),次取() = UAA
分節取碼
絕大多數的字皆已有明顯的分節,我們很容易取得其對應字碼。例如:
(部)字,取(、、) = LOB
(新)字,取(、、) = LTK
(給)字,取(、、) = SAO
(例)字,取(、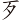 、) = PDR
、) = PDR
(份)字,取(、、) = PBD
(蒞)字,取(、、、) = RWPL
但若碰到四面包圍或是三面包圍的字形,很多時候是不會按著順序一口氣寫完,通常會被切開。比如說「國」字,前三筆劃是外圍分別左、上、右的一筆劃,接著是寫中間的「或」,最後一筆是外圍的下面那一筆劃。若要按照上述我們所舉的「部、新、給、例、份、蒞」方式來分節的話,勢必造成繁多的字根。因此,需要把部份部首或偏旁加以分節,給予合理的分類與歸納才行。因此,將將四面包圍型與三面包圍型的字根獨立起來,字根與字根的分界就可以一目瞭然。所歸納出的結果如下:
①將四面包圍型(如方框型)視為分水嶺(斷層)。在方框上方的字根先取,次取方框,再次取框內,尾取下方,把「方框」視為獨立單位。
例如:
(曹)字,取(、 、) = RFD
、) = RFD
(申)字,取(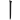 、、) = IQI
、、) = IQI
(油)字,取(、、) = WIQ
(呂)字,取(、、) = OPO
(頁)字,取(、、) = TMB
②將三面包圍型的根,如 「 」、「
」、「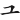 」、「
」、「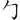 」、「」、「」、「」等字根,亦視為分水嶺。(獨立的單位)
」、「」、「」、「」等字根,亦視為分水嶺。(獨立的單位)
例如:
(易)字,取(、、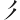 ) = DNM
) = DNM
(記)字,取(、、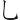 ) = IFL
) = IFL
(南)字,取(、、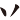 、
、 ) = JNBG
) = JNBG
(兩)字,取(、、 、) = ENBB
、) = ENBB
③還有一種三面包圍型:「」亦視為分水嶺(獨立單位),在「」 上面的字根先取,次取「」,再取下角。(有如攻城時,先攻城外,次取城牆,再取城內)。(請注意「」字根上面沒有一點,因為簡體字「烧」上面沒有一點)
例如:
(城)字,取( 、、、) = YAQN
、、、) = YAQN
(栽)字,取(、、、) = JAQT
(戒)字,取(、、) = AQR
(威)字,取(、、、 ) = AQPG
) = AQPG
(職)字,取(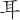 、、、) = RLAD 「」字根已省略。
、、、) = RLAD 「」字根已省略。
④將一點、兩點、三點、四點或其類似型亦視為獨立的單位。
例如:
(亦)字,取(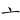 、
、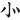 ) = LFA
) = LFA
(業)字,取(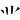 、、、
、、、 ) = FEBL
) = FEBL
(述)字,取(、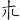 、
、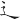 ) = ATW
) = ATW
(職)字,取(、、、) = RLAD
⑤尚有「 」、「
」、「 」、「
」、「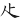 」、「」、「」、「
」、「」、「」、「 」、「
」、「 」、「
」、「 」、「」、「
」、「」、「 」等根亦視為分水嶺(獨立單位)。若能充分尊重分水嶺的獨立性,就很易於分節。而獨立的字根,除非被另一較大根所含蓋,否則不予分解。
」等根亦視為分水嶺(獨立單位)。若能充分尊重分水嶺的獨立性,就很易於分節。而獨立的字根,除非被另一較大根所含蓋,否則不予分解。
例如:
(主)字,取(、) = AKE
(年)字,取(、 ) = VSJ
) = VSJ
(錄)字,取( 、、、) = ACEW
、、、) = ACEW
(企)字,取(、) = BZE
(正)字,取(、) = EZE
(足)字,取(、) = OZN
(疋)字,取(、) = YZN
(政)字,取(、、) = EZP
(家)字,取(、、) = NEQ
(知)字,取(、、) = VDO
(除)字,取(、、) = BBH
⑥有兩旁相稱的根夾另一字根時,把被夾的字根分為上下兩個根。
例如:
(乘)字,取(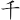 、、、) = GFFS
、、、) = GFFS
(爽)字,取(、、、) = JXXB
(喪)字,取(、、、) = JOOK